



Leaderboard
-
comment
Members2,168Points32,123Posts -
Wim Decorte
Members508Points5,935Posts -
eos
Members226Points1,600Posts -

Ocean West
Administrator196Points4,499Posts




Popular Content
Showing content with the highest reputation since 12/04/2010 in Posts
-
9 pointsThis post has been incorporated in to our site's guidelines. https://fmforums.com/guidelines9 points
-
5 points
-
5 pointsYa know, when you rate people with negatives, they will stop assisting you. Wouldn't you in their place? Why should we risk responding just to get slapped for it if you simply don't care for our response? You are judging whether our answers are right or wrong and you know very little about FileMaker. Would you let a podiatrist take out your gall bladder? No - you listen to those that know what you want to know. Soon, at this rate, you will have nobody left to help you. By the way, I am not responding ... I'm afraid to. Also, don't tell people to read the post again ... that is insulting. People here READ the posts. Your posts have been almost impossible to understand at all. That is not our fault. It is yours.5 points
-
No, you can't have pure separation. And yes, you might have to make more changes in the data file if your solution is still young (and occassionally throughout) but that is easily off-set by time saved not migrating. I've designed some large systems using both separation and not. Here are the reasons that *I* prefer using separation and these reasons probably aren't the top reasons at all - but they are important to ME: Transfer of Data (the best solution is NOT moving data) If you use single file and design in another version (so Users can continue working in the served version) you have to migrate the data from the served file to your file and that can take hours even when scripted. Every time you move the data, you risk something going wrong and the likelihood increases each time you migrate. With separation, the data file remains untouched. Import Mapping (unsafe and time consuming) Scripting the automatic export and import on every table in the single file solution takes time as well. Every export and import script must be opened and checked because you have added (and probably deleted) fields. You can make a mistake here. And even if you don’t, the 'spontaneous import map' bug might get you. It is very time-consuming and difficult, dragging a field around in the import maps (FM making it very difficult with the poor import mapping design). No data export/import or mapping with separation. Data Integrity (and User Confidence at risk) When working in a single served solution, you risk records not being created when scripts run (if you are in field options calculation dialog), triggers firing based upon incorrect tab order that you just changed on a layout, and a slew of insidious underground breaks most that you will never see until much later. By then, all you will know is that it broke but not why. You risk jangled nerves and lost faith of your Users who might experience these breaks, data loses, screen flashes and other oddities. A User’s faith in your solution is pure gold and it should not be risked needlessly. External Source Sharing (provide ‘fairly’ clean tables for integration needs) It has been discussed many times … why we have to wade through a hundred table occurrence names (particularly if using separation model anchor-buoy of which I'm not a fan anyway) and also have to view hundreds of calculations (which external sources don’t want). It can be a nightmare. Much better with a data file – where calculations are kept to minimum and the table occurrences are easily identifiable base relationships and easy to exchange with MySQL, Oracle and others. If FM made calculations another layer (separate from data) then FileMaker would go to the top instantly … rapid development front-end and true data back end. But I digress … Crashing (potential increases when Developing in live system) Working in developer mode (scripts with loops, recursive custom functions), means that there is higher likelihood of crashing the solution when designing - admit it. If you crash the solution while in the schema, it is (usually) instant toast but regardless, you SHOULD ALWAYS replace it immediately (run Recover, export the data and import it into a new clean clone). With separation model, you never design live so it is moot. No trashed file means no recover and no migration. You are designing as we all should … on a Development box. Transferring Changes (even if careful) Working in live single file system, a change you think is small might have unseen and unexpected side-effects. That potential danger increases as the complexity of your solution grows. This is why we all should beta test changes before going live. But even if careful and even if you design on Developer copy and test it, document your changes and then re-create those changes into the served file (eliminating the data migration portion completely), you risk mistyping a field name, script variable, not setting a checkbox and so forth. Separation also can risk error because it can mean adding a field or calculation to the Data file but it is very small percentage of the changes we make (except very early); most changes are layout objects, triggers, conditional formatting…UI changes. It is more difficult to replicate layout work between files. And most changes in the data file occur before the solution is even made live the first time. Same Developer experience (Developer works in single file regardless) In separation, all layouts and scripts reside in the UI no matter how many Data files are linked as data sources. The only time you have to even open the Data file is to work in Manage Database. Added ... or set permissions. Fewer Calculations (means faster solution?) If one decides to go with Separation, the goal is no calculations or table occurrences in the data file but that goal is not obtainable. Since this is your goal, you try to find alternate methods to achieve the same thing to avoid adding calculations (which you should do anyway). You will use more conditional formatting, Let() to declare merge variables, rearranging script logic to handle some of it … there are many creative options. And once you start down that path, you will find that you need fewer calculations than you ever imagined. Separation model means I can work safely on the UI aside and quickly replace it while leaving the data intact with the least risk. Some calcs need a nudge to update and privileges must be established in the data file as well – those are the only drawbacks I have experienced with it. I have never placed the UI on local stations. I have heard (from trusted sources) that it increases speed. There was a good discussion on separation model here: https://fmdev.filema...age/65167#65167 Everyone has their opinion. I did not want to go with separation and I was forced into it the first time (by a top Developer working with me, LOL). I am glad I was. Once I understood its simplicity and that everything happens in the UI, I was hooked. Of course if it is a very small solution for one person then I won't separate but for a growing business with data being served, I will certainly use it. Next time that, in your single-file solution, you go through a series of crashes because of network (hardware) problems and you have to migrate every night, think about separation. Next time you need to work in field definitions but can't because Users are in the system, think about separation. Most businesses are constantly changing and that means almost constantly making improvements to a solution. You can NOT guarantee that changes in Manage Database or scripts will not affect Users in the system. Risk is simply not in my dictionary when it comes to data. Enough can go wrong even when we take all precautions. I don't dance with the devil nor do I run with scissors. Joseph, I think it would be easier to start from scratch because it makes you re-think each piece. And, as you learn, you will find better ways of re-creating each portion of it. I would also wait until the next version arrives to take full advantage of its new features. It won't be long now.5 points
-
Actually, there is a way to measure it - but it takes quite a lot of work... MeasureBeforeDisplay.fmp124 points
-
4 pointsHey everyone, I love how open the Filemaker Community is, and how much is shared freely, so I wanted to contribute. I created a database to manage SVG icons. The icons are all royalty free provided by Syncfusion and there are about 4,000 icons, all with search tags to make finding them super easy. You can find out more about the file, and download it here: http://www.indats.com/2015/06/15/indats-icon-manager/ Please let me know any feedback you have on the file, thanks!

 4 points
4 points -
Hi All, I am happy to present the FmDynamix project, including cfCall () and #load (), my new 2 custom functions .... In an interest to further test FileMaker more and more ... I tried to give you a presentation of this new method, as explicit as possible, I hope to have succeeded ! You have the description and the presentation here, and take before the file demo : fmx_FmDynamix_Presentation.fmp12 I hope that this file will give you the urge to see this method, I do not think I have view of similar thing I hope that this "modularity" will please you and will give some ideas, feel free to test and give me your comments ! Thanks for your interest Agnès ( and thank you to Google Translate too )
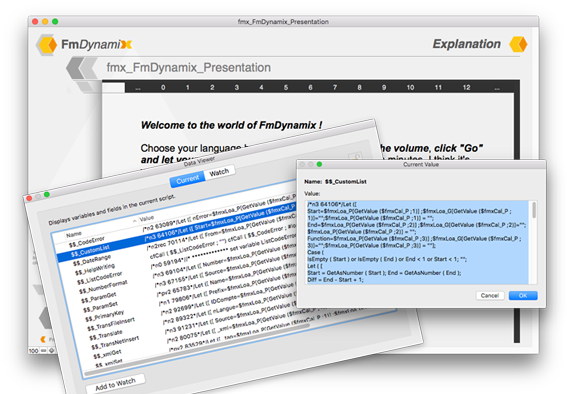 4 points
4 points -
4 pointsI was running some speed tests with EasySync recently and was surprised to see how long a sync took after I added a few images to the the sample record set that ships with EasySync. It was taking over 5 min. to download those records from FileMaker server which was installed on the same machine as FileMaker Pro. A competitor's product was doing the same sync in under 10 seconds. The interesting part was that all records in the sync took much longer to process, once the images were added. In other words, the fact that I added some images to record #1 made records #2-100 take exponentially longer to process. So, I did some digging and found that the entire payload was being saved to a local script $variable in the Pull Payload script. When the payload included images, that $variable was really large; too large to all fit into FileMakers available memory. This caused the number of page faults to increase by about 600,000 while the records were being processed. My theory was that if I could reduce the amount of data store in memory (variables) at once, then I could reduce the time it takes to process a large payload. It turns out this basic concept worked. The sync which previously took over 5 min. now only took 30 seconds! (and page faults barely increased at all) I've attached a file with these changes that prove my theory. I ended up saving each segment returned from the server to a new record in the EasySync table, then only extracting a single record at a time from the payload, reading from each payload segment as necessary. NOTE: the attached file is a proof of concept ONLY! Please do not use it as-is in a production; it has not been tested and will probably fail in all but the most obvious circumstances. Also, my system crashed once while I was working on this file, so it's been closed improperly at least once. DO NOT USE IT IN PRODUCTION! I think I may start a fork of this project which includes this change; I'll post back here if I do. FM_Surveys_Mobile_v1r3_DSMOD.fmp124 points
-
4 points
-
4 pointsThis post is simply to make others aware of a usage of placeholder text that I haven't seen mentioned before. We have situation where, when opening a popover to create a new record, the new record isn't created until the User enters data. However, there are a few auto-enter fields which are defaults and they do not display. This is confusing to Users since, from their perspective, that data should already be there - they don't fill it in unless they want to change the value.! I always keep a field (global) called PLACEHOLDER. It is set to auto-enter ( replace ) with: If ( not IsEmpty ( Self ) ; "" ) and I use it for displaying calculation results on layouts when merge fields will not work but this usage is a bit different ... The PLACEHOLDER field can help with displaying these default auto-enters. No record has been created yet (and may not be if User cancels) but I have set those field's placeholder text to their auto-enter calculation and I've set the placeholder text style to same font color as their regular text. Now default entries display. BTW, this works nicely since when User enters the field, the value remains until the user starts to type, at which time the placeholder text disappears and the user entry displays.
 4 points
4 points -
4 pointsThis feature is huge. Now that FileMaker 14 has been released here's the not-secret-anymore topic of my devcon presentation: Thursday, July 23 | FileMaker Developer Conference 20154 points
-
4 pointsAnother fun option. If you want to get away from the overhead of the conditional formatting. Thanks to @jbante for posting this one. http://uxmovement.com/forms/why-infield-top-aligned-form-labels-are-quickest-to-scan/ I've been playing around with this idea for just over a week now. Noticing layouts built this way look less busy, but still provides all of the info a user needs to know what data in a field. Something that can be lost if the label is hidden. Google does this a lot in their interface ( hiding interface objects and menus ), to the point where it's not intuitive, and you can't find the magic spot for where the menu is hidden.
 4 points
4 points -
4 pointsSo, I finally took the plunge and upgraded the site to the new forum engine. I am planning to work the weekend to restore site features that are currently disabled. There may be times when the site goes unresponsive or generates an error. I already have a few trouble tickets pending with the site developers to provide a remedy. I wish to thank the Site Advertisers for making this possible, but do please forgive the irony as I don't have all the ad spaces working just yet and I hope to restore them as soon as possible. - Having to crash course some html/php/css logic. Think I'll need another cuppa I hope to have some site instructions as things have changed a bit. One thing you may have noticed is that before we had usernames and Display Names the site only allowed one so we elected Display Names as they were already public facing - so you will need to login using your Display Name or your email address, or if already configured Facebook or Twitter (hope to include other oAuth login methods in the future ) I'll post more in this topic when there is something you should know.4 points
-
4 pointsI suggest that every act which could have been optimised but wasn't is poor practice. It is not poor practice because of principle but rather because of: If you let slide optimisation in this area on 2,500 records, the next time you'll be inclined to think letting slide with 3,000 records is fine. It is a slippery slope which breeds sloppiness and drags a good solution down into less than ideal. We can not always predict the environment and venue our solutions will be fired under. It may be fine over LAN but when accessed from an iPad with low-grade provider, the process which only took a blink over LAN now takes 4 seconds and THAT is a LONG time to a User. As for me, if I go to a website which takes more than 6 seconds to load, I move on. Users today will not tolerate slop. Compounded, each of the blow offs which were small, now each contribute to network traffic and begin to crawl. Do not give in. Optimize everything you do at all times. It is one of the few things you can control and it is the best investment in your solution. You may think you are only saving one second but multiply that over six months, performed by 25 users and you see clearly where this is going. Do not fall for the disease of sloppiness. Commit to excellence in your work. And yes, it is only my opinion because my opinion is the only one I have to share. And yes, I'm an obnoxious idealist. If that is the worst I am called, I'll take it.4 points
-
4 pointsYour "Maior Grid Spacing" is setted to 1 point. You need to change it to something like 10 or more. Or you need to unchek the box: View >> Grid >> Show Grid4 points
-
4 pointsCharity, Since the best experience is if the end user has all the data they need local to their iPad and not rely on connectivity you may try to do this: Create your solution in ONE file with multiple tables one table for your catalog another other table for your customer data entry. If your catalog only changes every so often that is fine you can push out a new version to the end user to replace their database with all the catalog data. If they only need to add new customers and not look up historical customers then you can essentially have them email data (export as TAB/CSV/or EXCEL ) from the customer table for you to import in to your own file, every night. (not ideal but its a work around) Since cost is a concern for you please look at this http://fmeasysync.com, its a free open source framework for syncing your database - it may be a bit overwhelming at first but I am confident that you can get there! - Charity every year at the developer conference we (old salts) wonder where the "next generation" of FileMaker Developers are coming from, if you have a passion for this and accept the challenges head on, you most likely will be reciprocating your learnt knowledge and wisdom in short time to other newbies jumping in to the fray. - What goes into the External Data Sources - really depends on where the files will ultimately be deployed, if two files are hosted then they would use relative paths: file:MyDatabse.fmp12 if one file is local to a device then it needs the fully qualified URL path with either the PUBLIC IP address, or a domain name, if using a 10.0.x.x or 192.168.x.x this is an internal IP address and wouldn't be accessible out side your environment. fmnet:/192.168.10.10/MyDatabase.fmp12 fmnet:/fms.somehostingcompany.com/MyDatabase.fmp12 if you would like to see how can be access when hosted please send me a private message and I could host a sample file for you that you can test with. Stephen4 points
-
4 pointsI know this is lower priority than some of the other wishes but I can't help but just mention it ... If we go to Manage > Themes, we see a list of themes loaded in this file and it also indicates how many layouts are assigned to that theme. But it would be nice if we knew which layouts were assigned to a theme and even had the ability to ... yeah I know ... probably never ... but to GTRR (so-to-speak) to those layouts or see a list of them at least. Manage > Layouts certainly has room to list its theme along with the table and menu set. If nothing else, this would make life easier for us. When a solution has 150 layouts, it can take quite a bit of time to go through them all to find the few layouts assigned to a theme needlessly. And each theme (even themes unused), load all definitions and take up quite a bit of space. For instance, a recent example - file had 13 themes but on 3 were used. By converting them all to the single theme, I saved 1.7MB right off the top and it took 15 minutes. So a way to quickly jump to layouts according to their theme would be helpful. Or ... am I missing something here? Are there ways of seeing a list of layout names per theme? Thanks everyone for listening and hopefully providing a solution of which I was unaware. Otherwise I'll provide FileMaker feedback about it. Also, there is a Custom Themes forum for FM12 but there isn't one for FM13. It might be nice to remove the 'FM12' portion from the forum title so we can put FM13 questions there as well ... or ... create another forum for Custom Themes in FM13. I prefer the former. Thank you!!4 points
-
4 pointsIt's perfectly find, even preferable, to keep your process split out into separate scripts. There are plenty of arguments for this from different sources, but I personally think that the best reason is that human working memory is one of the biggest bottlenecks in our ability to write software. It's dangerous to put more functionality in one script (or calculation, including custom functions) than you can keep track of in your head. If you find yourself writing several comments in your scripts that outline what different sections of the script do to help you navigate the script, consider splitting those sections of the script into separate sub-scripts, using the outline comments for the sub-script names. If your parent scripts start to read less like computer code and more like plain English because you're encapsulating functionality into well-named sub-scripts, you're doing something right. (The sub-scripts don't have to be generalized or reusable for this to be a useful practice. Those are good qualities for scripts, but do the encapsulation first.) I think you'd be better off if the scripts shared information with script parameters and results instead of using global variables, if you can help it. When you set a global variable, you have to understand what all your other scripts will do with it; and when you use the value in a global variable, you have to understand all the other scripts that may have set it. This has the potential to run up against the human working memory bottleneck very fast. With script parameters and results, you only ever have to think about what two scripts do with any given piece of information being shared: the sub-script and its parent script. Global variables can also lead to unintended consequences if the developer is sloppy. If one script doesn't clear a variable after the variable is no longer needed, another script might do the wrong thing based on the value remaining in that global variable. With script parameters, results, and local variables, the domain of possible consequences of a programming mistake are contained to one script. I might call it a meta best practice to use practices that limit the consequences of developer error. Globals are necessary for some things; just avoid globals if there are viable alternative approaches. There is a portability argument for packing more functionality into fewer code units — fewer big scripts might be easier to copy from one solution into another than more small scripts. Big scripts are also easier to copy correctly, since there are fewer dependencies to worry about than with several interdependent smaller scripts that achieve the same functionality. For scripts, this is often easy to solve with organization, such as by putting any interdependent scripts in the same folder with each other. Custom functions don't have folders, though. For custom functions, another argument for putting more in fewer functions is that one complicated single function can be made tail recursive, and therefore can handle more recursive calls than if any helper sub-functions are called. This ValueSort function might be much easier to work with if it called separate helper functions, but I decided that for this particular function, performance is more important.4 points
-
Do an ExecuteSQL to do a quick select, if that comes up empty you can skip the real FM find. It's important to understand though that "Set Error Capture On" does not prevent the error from *happening*. The only thing it does is hide the error from the user so that you can handle it silently. If you run the same script in your debugger you will see that FM also reports the error.4 points
-
4 pointsThe trick is to use the fmsadmin command line and that syntax is the same on Windows and Mac. So the only challenge is in calling that fmsadmin command line from your favourite OS scripting language: shell script / AppleScript on OSX and batch file / VBscript / PowerShell on Windows. Below is a sample VBscript that automates shutting down FMS in a safe way. It should contain enough pointers to do the reverse. ' Author: Wim Decorte ' Version: 2.0 ' Description: Uses the FileMaker Server command line to disconnect ' all users And close all hosted files ' ' This is a basic example. This script is not meant as a finished product, ' its only purpose is as a learning & demo tool. ' ' This script does not have full Error handling. ' For instance, it will break if there are spaces in the FM file names. ' The script also does not handle infinite loops in disconnecting clients ' or closing files. ' ' This script is provided as is, without any implied warranty or support. Const WshFinished = 1 q = Chr(34) ' the " character, needed to wrap around paths with spaces '-------------------------------------------------------------------------------------------- ' Change these variables to match your setup theAdminUser = "" theAdminPW = "" pathToSAtool = "C:Program FilesFileMakerFileMaker ServerDatabase Serverfmsadmin.exe" '-------------------------------------------------------------------------------------------- SAT = "cmd /c " & q & pathToSAtool & q & " " ' watch the trailing space callFMS = SAT If Len(theAdminUser) > 0 Then callFMS = callFMS & " -u " & theAdminUser End If If Len(theAdminPW) > 0 Then callFMS = callFMS & " -p " & theAdminPW End If listClients = callFMS & " list clients" disconnectClients = callFMS & " disconnect client -y" listfiles = callFMS & " list files -s" closeFiles = callFMS & " close file " stopServer = callFMS & " stop server -y -t 15" ' hook into the Windows shell Set sh = WScript.CreateObject("wscript.shell") ' get a list of all clients and force kick them off clientIDs = getCurrentClients() clientCount = UBound(clientIDs) ' loop through the clients and kick them off If clientCount > 0 Then fullCommand = disconnectClients Set oExec = sh.Exec(fullCommand) ' give FMS some time and then requery the list of clients Do Until oExec.Status = WshFinished WScript.Sleep 50 Loop Do Until clientCount = 0 WScript.Sleep 1000 Debug.WriteLine "Waiting for clients to disconnect..." clientIDs = getCurrentClients() clientCount = UBound(clientIDs) Loop End If ' get list of files and close them fileIDs = getCurrentFiles() fileCount = UBound(fileIDs) ' loop through the files and close them If fileCount > 0 Then Do Until fileCount = 0 fullCommand = closeFiles & fileIDs(0) & " -y" Set oExec = sh.Exec(fullCommand) ' give FMS some time and then requery the list of files Do Until oExec.Status = WshFinished WScript.Sleep 50 Loop fileIDs = getCurrentFiles() fileCount = UBound(fileIDs) Loop End If ' all clients and files stopped ' shut down the database sever (does not stop the FMS service!) fullCommand = stopServer Set oExec = sh.Exec(fullCommand) Do Until oExec.Status = WshFinished WScript.Sleep 50 Loop ' done, exit the script Set sh = Nothing WScript.Quit ' ------------------------------------------------------------------------------ Function getCurrentClients() tempCount = 0 Dim tempArray() Set oExec = sh.Exec(listClients) ' in case there are no clients... If oexec.StdOut.AtEndOfStream Then Redim temparray(0) ' read the output of the command Do While Not oExec.StdOut.AtEndOfStream strText = oExec.StdOut.ReadLine() strText = Replace(strtext, vbTab, "") Do Until InStr(strtext, " ") = 0 strText = Replace (strtext, " ", " ") Loop If InStr(strText, "Client ID User Name Computer Name Ext Privilege") > 0 OR _ InStr(strText, "ommiORB") > 0 OR _ InStr(strText, "IP Address Is invalid Or inaccessible") > 0 Then ' do nothing Redim temparray(0) Else tempClient = Split(strtext, " ") tempCount = tempCount + 1 Redim Preserve tempArray(tempCount) tempArray(tempCount-1) = tempClient(0) End If Loop getCurrentClients = tempArray End Function Function getCurrentFiles() tempCount = 0 Dim tempArray() Set oExec = sh.Exec(listfiles) ' in case there are no files... If oexec.StdOut.AtEndOfStream Then Redim temparray(0) ' read the output of the command Do While Not oExec.StdOut.AtEndOfStream strText = oExec.StdOut.ReadLine() strText = Replace(strtext, vbTab, "") Do Until InStr(strtext, " ") = 0 strText = Replace (strtext, " ", " ") Loop If InStr(strText, "ID File Clients Size Status Enabled Extended Privileges") > 0 OR _ InStr(strText, "ommiORB") > 0 OR _ InStr(strText, "IP Address Is invalid Or inaccessible") > 0 OR _ Left(strtext, 2) = "ID" Then ' do nothing Redim temparray(0) Else tempFile = Split(strtext, " ") status = LCase(tempFile(4)) If status = "normal" Then tempCount = tempCount + 1 Redim Preserve tempArray(tempCount) tempArray(tempCount - 1) = tempFile(1) & ".fp7" End If End If Loop getCurrentFiles = tempArray End Function4 points
-
4 pointsWhy not load all their information into one global variable and then you can always parse out that info since you should only ever have one row returned. ExecuteSQL ( "SELECT ID, firstname, lastname, title, date_hire FROM Staff WHERE accountName = ?" ; "¶" ; "" ; Session::accountName ) Then you can use GetValue ( ) to parse out specific information.4 points
-
This is kind of janky, but you have to insert in a script step that guarantees no error code thrown (like "Show All Records") and then exit the script using the "Exit Script" step. ie. If Get(lastError) > 0 action for failed find Show All Records Exit Script Else action for successful find End If If you have multiple "Perform Find"s, make sure you add the "If Get(lastError) > 0" right after the Perform Find and then "Show All Records" and "Exit Script" steps after your other script steps but before the "End If" or "Else" script step. This suppresses the error in the schedule section of FMS4 points
-
The two main schools of thought for passing multiple script parameters are return-delimited values and name-value pairs — the choice is a matter of taste, whether you prefer array or dictionary data structures. Both approaches have solutions for dealing with delimiters in the data. For return-delimited values, you can use the Quote function to escape return characters, and Evaluate to extract the original value: this standard. As long as you have a function to define a name-value pair in a parameter (# ( name ; value)) and another function to pull specific values back out again (#Get ( parameters ; name )), it works, and all variations should behave the same way. Any other supporting functions are purely for convenience, and probably can be re-implemented for whatever representation syntax you want. So I'd write: Quote ( "parameter 1") & ¶ & Quote ( "parameter 2¶line 2" ) will give you the parameter: "parameter 1" "parameter 2¶line 2" and you can retrieve the parameters: Evaluate ( GetValue ( Get ( ScriptParameter ) ; 2 ) ) with the result: parameter 2 line 2 Every name-value pair approach worth using has it's own approach for escaping delimiters. In my own opinion, XML-style syntax is unnecessarily verbose. My personal preference when working with name-value pairs these days is "FSON" syntax (think "FileMaker-native JSON"), which is where the parameters are formatted according to the variable declaration syntax of a Let function: $parameter1 = "value 1"; $parameter2 = "value 2¶line2"; I only consider name-value pair functions practical when the actual syntax is abstracted away with custom functions. Once you do that, the mechanics of working with the different types should be interchangeable, such as any name-value pair function set that matches # ( "parameter1" ; "value 1" ) & # ( "parameter2" ; "value 2¶line 2" ) and: #Get ( Get ( ScriptParameter ) ; "parameter2" ) I only have 2 requirements for any parameter-passing syntax: 1. It can encode it's own delimiter syntax as data in a parameter, and therefore any text value (already mentioned in this thread), and 2. it can arbitrarily nest parameters, i.e., I can include multiple sub-parameters within a single parameter. The requirements tend to work hand-in-hand with each other. If I can do those two things, I can construct everything else I will ever need within that framework.4 points
-
Hi Charity, We all deal with wanting to eliminate the display of buttons, checkboxes, drop-down calendars and such on that last row when Allow Creation is in effect. Instead of having to eliminate the objects individually, you can accomplish it all with conditional formatting AND make it clear to your User that they click the last row to add a new record. Here is how: Create a text box with the words [ Add new record here ... ] Make the background transparent. Color of text does not matter Resize the text box to same size as single portal row Format the text box as follows (using conditional formatting) First entry: Formula = not IsEmpty ( the primary key from the portal table occurrence ). Then below select ‘more formatting’ and set the font size to custom and 500. Second entry: Formula = IsEmpty ( the primary key from the portal table occurrence ). And below set the text to white and the background to black as example. You can set it anything you wish. Select this text box and Arrange > Bring to Front and place it over your top portal row. This one text box hides checkboxes, drop-down calendars, buttons, lines on empty fields, etc only on the empty row and also provides a clean row in which to provide your message. I use it on all Allow Creation portals - just by changing the ID referenced within the conditional format portion.4 points
-
@LaRetta shared this sample file with me @comment and I really liked the concept so I played around with it a little. I was able to accomplish the same result with a single layout, which means I'd be more likely to use this technique myself. I also added layout objects so I could measure the various part sizes rather than having to keep a layout size and script config in sync; this is optional and only my preference for maintenance reasons, though. @IlliaFM Since you just mentioned a footer, I added that to my sample file as well. If you try to use my alternate implementation of this technique, be aware there are two fields layered on top of each other that probably only look like one field at a glance. This doesn't solve the other issues @comment just mentioned, though. MeasureBeforeDisplayDS.fmp123 points
-
Here's a table showing what happens at each step, for each possible value of Month(), starting with September: Month ( SalesDate ) 9 10 11 12 1 2 3 4 5 6 7 8 Month ( SaleDate ) - 9 0 1 2 3 -8 -7 -6 -5 -4 -3 -2 -1 Mod ( Month ( SaleDate ) - 9 ; 12 ) 0 1 2 3 4 5 6 7 8 9 10 11 Div ( Mod ( Month ( SaleDate ) - 9 ; 12 ) ; 3 ) 0 0 0 1 1 1 2 2 2 3 3 3 As you can see, any month in the first quarter will now have the value of 0, the next 3 months will return 1, and so on. All that remains is to add 1 and prepend the Q character to get the expected Q1 to Q4 numbering. --- Conceptually, there are two steps taking place here: Renumber the months so that September is moved to the beginning of the year; Divide them into groups of 3.3 points
-
I would call that "two days before" rather than "three days, inclusive". Otherwise you'll find yourself saying that a date is one day before itself, "inclusive".😀 Now, assuming that is the wanted logic, there is a non-recursive solution - but it cannot account for holidays. OTOH, with only a few steps to take one could do: While ( [ // start at end of month of given date start = Date ( Month ( YourDate ) + 1 ; 0 ; Year ( YourDate ) ) ; n = 2 ] ; n ; [ workday = IsEmpty ( FilterValues ( DayOfWeek ( start ) ; "1¶7" ) ) ; start = start - 1 ; n = n - workday ] ; Day ( start ) ) and this would be to easy to adapt so that it looks at list of holidays and does not advance the counter if the date is listed. --- ADDED: Note that this can return a weekend date if, for example, the end of the month is a Tuesday. To always return a workday, you can change the condition to: n or not IsEmpty ( FilterValues ( DayOfWeek ( start ) ; "1¶7" ) ) ; When I have more time, I will try and find way to eliminate the double evaluation of the IsEmpty (...) expression.3 points
-
Keep in mind that Filemaker accepts (and stores) dates with or without leading zeros. If user has entered the date as "1/5/2021" then filtering the field to keep digits only will result in "152021". If you want to be sure that the days and months are padded to 2 digits, use: SerialIncrement ( "00" ; Day ( YourDatefield ) ) & SerialIncrement ( "00" ; Month ( YourDatefield ) ) & Year ( YourDatefield ) or shortly: SerialIncrement ( "00000000" ; 10^6 * Day ( YourDatefield ) + 10^4 * Month ( YourDatefield ) + Year ( YourDatefield ) ) (I am assuming from your example that the format you want is DDMMYYYY.)3 points
-
No, you wouldn't. You will see why in a moment. In order to produce a return-delimited list of individual count of each value, you could do a calculation like this: While ( [ listOfTypes = YourSummaryField ; uniqueTypes = ValueListItems ( "" ; "YourValueListName" ) ; n = ValueCount ( uniqueTypes ) ; i = 1 ; result = "" ] ; i ≤ n ; [ result = List ( result ; ValueCount ( FilterValues ( listOfTypes ; GetValue ( uniqueTypes ; i ) ) ) ) ; i = i + 1 ] ; result ) This will return a list of counts of each value, in the order of the value list. But for a chart - esp. if it is a pie chart - you want to list the most frequent values first. This is very easy to do if you let the chart tool work as intended (i.e. chart the found set, with a data point for each group) and sort the records by type, descending with reorder based on a summary field that counts the records. Replicating this functionality in a calculation would be very difficult.3 points
-
3 pointsFirst, you have a misnomer: the thing you are are trying to produce is not a "shopping list". It is a BOM (Bill Of Materials). Look it up, it's a thing. Next, having the numbers you need "scattered throughout the database in various join tables" is not a good idea. The preferred structure is a table of Items that lists all materials, sub-assemblies and final products. This table is joined to itself in a many-to-many relationship (one item can have many components; one item can be used by many assemblies), using a single join table. On Filemaker's relationships graph, this could look like: Now, to produce the actual BOM for an assembly, you can either drill-down from the assembly to its components, and then to their components, and so on until you reach the raw materials (i.e. items that have no child components), or let the quantities "bubble up" from the components to their parent assemblies. Neither one of these is particularly simple, and if you're not at least an intermediate-level developer, then this is not a good project for you. I will roughly outline the "bubble-up" approach because I believe it is easier. However, it needs to be said that this is a cascading calculation and Filemaker places a limit (a few hundred, IIRC) on the length of the chain of a cascading calculation. The basic idea is that each record in the items table computes a list of its components and their qualities. And each record in the join table multiplies the quantities listed in its component's list by its own quantity, and passes the result to its parent assembly record to compute a new list. The list itself could be in a text format (a row for each entry, with a separator between the quantity and the item), or it could be two return-separated lists (one for quantities, one for item IDs), or it could be JSON. So eventually each item has a list of all the raw materials used to produce it and their quantities. However, the list may easily contain multiple entries for the same material. These entries need be grouped and summarized - and again, this could be done using several methods - for example, by using a technique known as "virtual list" table. Hopefully this can help steer you in the right direction - or scare you off, which sometimes is the correct path to take.🙂
 3 points
3 points -
Actually, come to think of it, there is a non-recursive way: Let ( [ values = Substitute ( text ; [ "," ; ¶ ] ; [ "x" ; "¶x" ] ) ; filter = Substitute ( values ; "¶x" ; "¶yx" ) ; mutlipliers = FilterValues ( values ; filter) ] ; Substitute ( mutlipliers & ¶ ; [ "¶¶" ; "" ] ; [ ¶ ; "+" ] ) ) But it may take some time to understand how this works.3 points
-
Does the attached test work for you? InsertFromRedirectURL.fmp123 points
-
3 pointsWell, I suggest you put some restriction on the number of allowed values, because otherwise this gets (even more) complicated. Some background: Your question is a variation of the subset sum problem, which in turn is a special case of the knapsack problem. Both are VERY difficult problems to solve programatically. Even worse, the known solutions are difficult to implement in Filemaker, because its calculation engine has no arrays. Fortunately, with a small number of values, a naive brute-force solution is feasible: enumerate all possible combinations of the given values, calculate the sum of each combination, and compare it to the target sum. The attached demo is designed to deal with up to 7 values. It has 127 records to enumerate the 2^7 -1 = 127 possible combinations, and a repeating calculation field with 7 repetitions to list the values of each combination. You can extend the limit by adding more records and more repetitions, but - as I said - this is a brute-force approach and it will get slower as the number of values increases. SubsetSum.fmp123 points
-
3 points
-
I can finally report resolution of a longstanding problem, in hopes that it might be useful to someone else. The short version of my client’s sad saga, is that container documents in secure external storage were damaged by the IT company’s monthly restarts of the FM Server VM for OS patches. Further troubleshooting determined that even restarting the FM Service would completely destroy the container documents. The documents were stored with all FM data on drive E. New test databases on Drive E experienced the same fate, where server or service restarts damaged the container documents. Further testing showed that a fresh copy of the same test database, when installed on Drive C, survived restarts with all container documents intact. New testing on Drive G reproduced the same problems as on Drive E. The client’s IT company created a new VM, and we installed using the same setup as on the production system: OS and FM Server on Drive C, Data on E, Backups on G. The same problems occurred on restart, i.e. all container documents damaged beyond any possible access. Next we uninstalled FMS 16 and installed FMS 17 on the tester VM, and discovered during configuration that container document storage was not allowed nested in Drive E; instead, FMS would support only container storage at the root level of the external drive. For the first time, restarts did *not* damage the secure external container documents. And we had our clue: try the container folder at the root, not nested. Then we uninstalled FMS 17 on the tester VM, and reinstalled FM 16.0.v4, but this time we put the container documents at the root on Drive E. Voila! No container documents were harmed by any restarts. So the moral of the story is that secure external container storage, on FMS 16 on an external drive, needs to be in a folder at the root, not nested. So we went back to the production system, changed the location of the container folder, and no problems have occurred after any restarts. Thanks to all who helped along the way, and especially Wim Decorte. Environment: FMP 16.0.3 running on the client agency’s “RDS Farm”, a Windows 2008 VM. 35 users. Server 16.0.4 hosted on Windows Server 2012.3 points
-
May I suggest that you work with this version going forward. It clarifies key field names, reorganizes the graph, and eliminates "portal" from any table or relationship names. The TO may be used in a portal. But labeling the TO as someThing_someThingPortal hides actual relational concepts. Test File DemoJOBR.fmp12
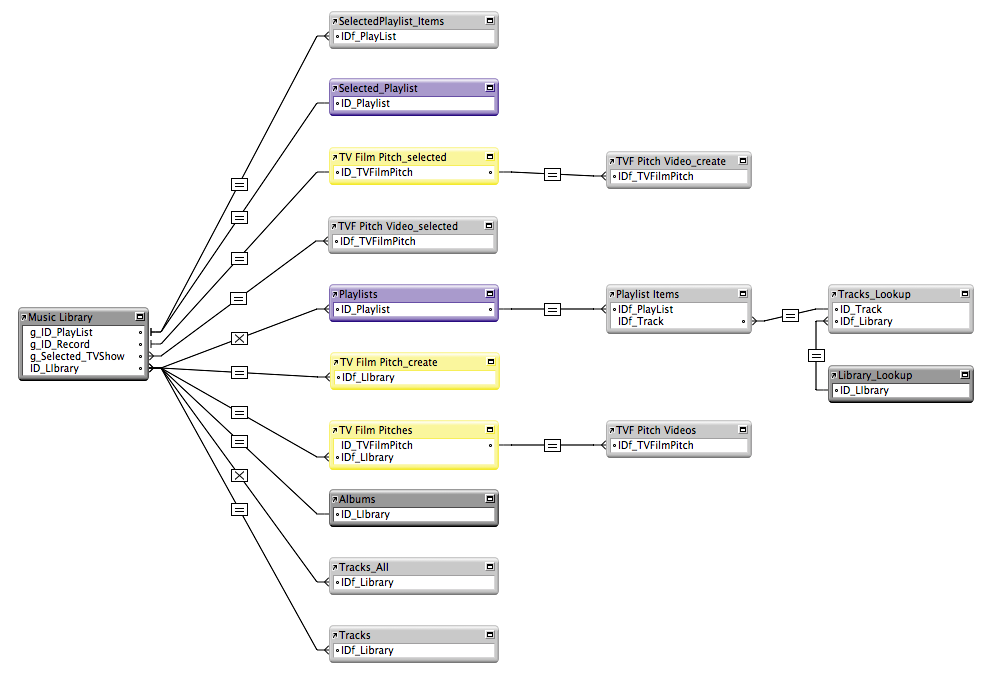 3 points
3 points -
3 pointsNot sure in what form you need the results. Here's your file back with two global fields that contain a list of unique skus and the count of that field (set by script). DEMOv2.fmp123 points
-
3 pointsThere is a file called permittedlist.txt. It is located in the /Users/{username}/Library/Application Support/FileMaker/Shared folder. This Library folder is normally hidden. To view it, go to Finder and open the Go menu while holding down the option key. The option key allows you to select the Library folder. Drill down to this file, permittedlist.txt and delete it. Or, to be ultra-cautious, just rename it. Now, when you try to upload a database to FM Server, it will alert you to any SSL certificate issues. When you choose to connect anyway, it will generate a new permittedlist.txt and it will allow you to freshly enter your FM Server admin name and password and upload the file.3 points
-
Let's all get along? It's been rare for our forums, but on occasions I have had to step in to keep the peace and harmony of the site. At times personalities clash - and the typed repsonses are often done in haste - and the sort of thing that wouldn't be said if we were all in same room together. I am encouraging everyone to re-read https://fmforums.com/guidelines/ our guidelines. Let's please keep threads on topic. - and not abuse the "reporting" system. Please be courteous of others and if you have offended someone please extend a sincere apology. The least thing I enjoy doing is to put people in 'timeout' or ban them from the site. Thank you.3 points
-
3 pointsAleesha, another thing which fits for you right now is making it easy on yourself in future to know specifically which table occurrences have Allow Creation turned on. It looks obvious here but as your solution grows, it won't always be obvious and we can forget as well. What many developers do is use the text tool to create reminders such as the A or a - if 'deletion' or S for sort.
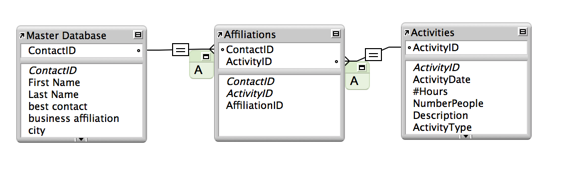 3 points
3 points -
Couldn't this be much simpler? AppleScriptSpeak.fmp123 points
-
OK - I did it myself. Over a couple weekends of spare time, I wrote a few dozen scripts that interface between Filemaker and the Amazon Marketplace Web Service API. Sad to say, this is non-trivial. Amazon's documentation is poor: there are a surprising number of mistakes, misspellings, and obsolete/outdated sections. The one bright spot is the Amazon MWS Scratchpad, which provides a direct sandbox to allow testing different calls. Most of the documentation and online help is aimed at PHP & Java & Python developers; it's not too difficult to map this into Filemaker land. I wrote scripts to gather my orders from Amazon Market Place, and to send confirmations to buyers. Like most API's, there are many gotcha's. Here's a few hints, mainly to save time for others in my position. 1) A simple Filemaker WebViewer is *not* going to work, unless you do screen-scrapes from the Amazon MWS Scratchpad. 2) I used cURL to communicate with Amazon Web Service via POST. The information to be POSTed is the Amazon parameter string (which includes the hashed signature). The Monkeybread Software Filemaker functions (www.mbsplugins.eu) are just the ticket. 3) The outgoing information must be signed with a SHA256 hash. Again, this is available in the Monkeybread software functions. Use MBS("Hash.SHA256HMAC"; g_AWS_Secret_Key; g_AWS_Text_to_Sign_With_NewLines_Replaced; 1) 4) Getting the correct SHA256 signature requires very strict observance of line-feeds ... carriage return / linefeeds in OS X and Filemaker will cause a bad signature. Before making the SHA256 hash, do a complete replace so as to generate only Unix-style line-feeds. Within the "canonical parameter list" there aren't any linefeeds (but there are linefeeds before that list) 5) The Amazon API demands ISO-8601 timestamps, based on UTC. Filemaker timestamps are not ISO-8601, but there are several custom functions to generate these. The Filemaker function, get(CurrentTimeUTCMilliseconds), is very useful, but its result must be converted into ISO-8601. Notice that Amazon UTC Timestamps have a trailing "Z" ... when I did not include this, the signatures failed. 6) The Amazon API must have url encoded strings (UTF-8). So the output from the SHA256 hash must be converted to URL encoding -- again, the Monkeybread software comes through (use MBS function Text.EncodeToURL) 7) The Amazon "canonical parameter list" must be in alphabetical order, and must include all of the items listed in the documentation. 8) Errors from Amazon throttling show up in the stock XML return, but check for other errors returned by the cURL debug response. At minimum, search through both responses by doing a filemaker PatternCount (g_returned_data; "ERROR") 9) When you're notified of a new Amazon order, you must make two (or more) cURL calls to Amazon MWS: 1) first, do cURL request to "list orders", which will return all the Amazon Order Numbers (and some other info) for each order since a given date/time. 2) Then, knowing an order number, you do another cURL to get all the details for a given order. Repeat this step for every new Amazon order number. Each of these calls requires your Amazon Seller_ID, Marketplace_ID, Developer_Account_Number,_Access_Key_ID, and your AWS_Secret_Key. Each also requires a SHA-256 hash of all this information along with the "canonical parameter list" If anyone wants my actual scripts, drop a note to me (At this moment, my scripts do the all-important /orders /list orders and /get order. I'm almost finished writing a /feeds filemaker API to send confirmations. I probably won't build scripts to manage inventory or subscriptions, but once you've built a framework for the scripts, it's not difficult to expand to more functionality) Best of luck all around, -Cliff Stoll3 points
-
3 pointsSuppose you have a variable named $word, holding two numbers separated by a hyphen. After running: Set Variable [ $range; Value:Substitute ($word; "-"; " " ) ] Set Variable [ $rangeStart; Value:GetAsNumber ( LeftWords ( $range ; 1 ) ) ] Set Variable [ $rangeEnd; Value:GetAsNumber ( RightWords ( $range ; 1 ) ) ] Loop Exit Loop If [ $rangeStart > $rangeEnd ] Set Variable [ $enum; Value:List ( $enum ; $rangeStart ) ] Set Variable [ $rangeStart; Value:$rangeStart + 1 ] End Loop you will have a variable named $enum holding a list of all the numbers within the range.3 points
-
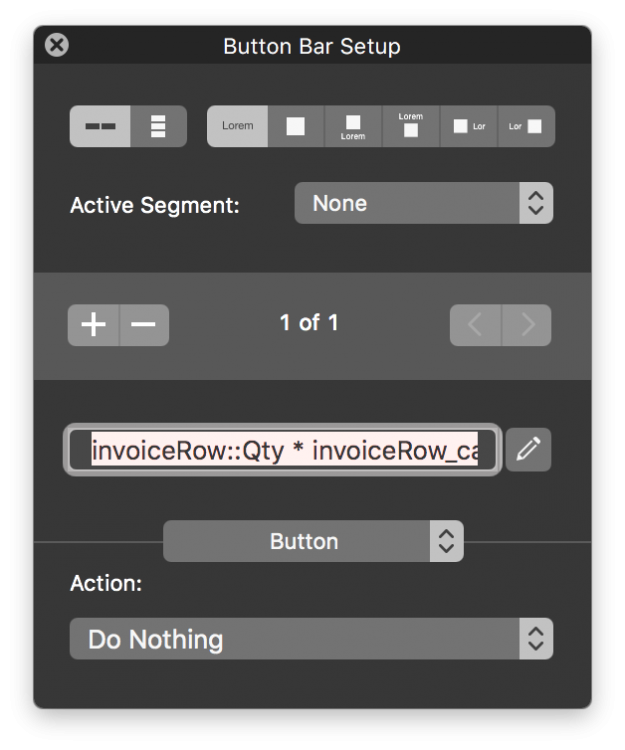
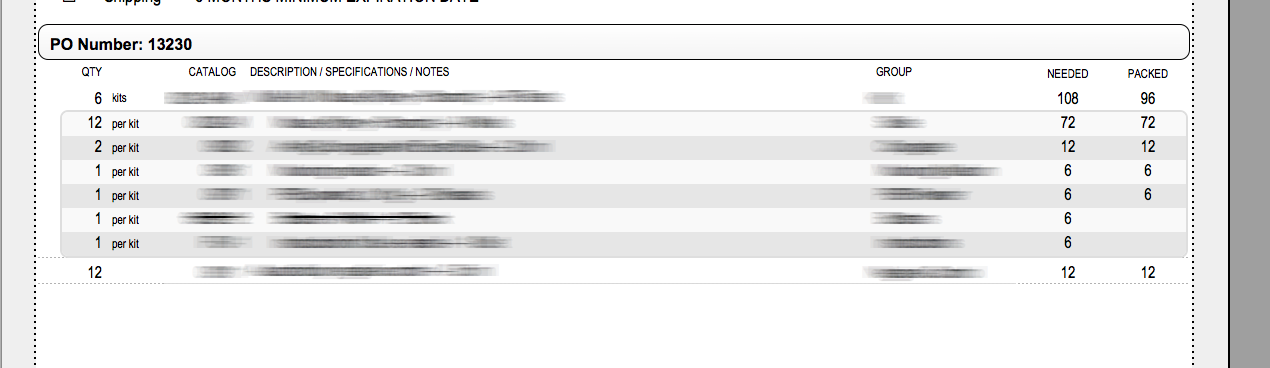
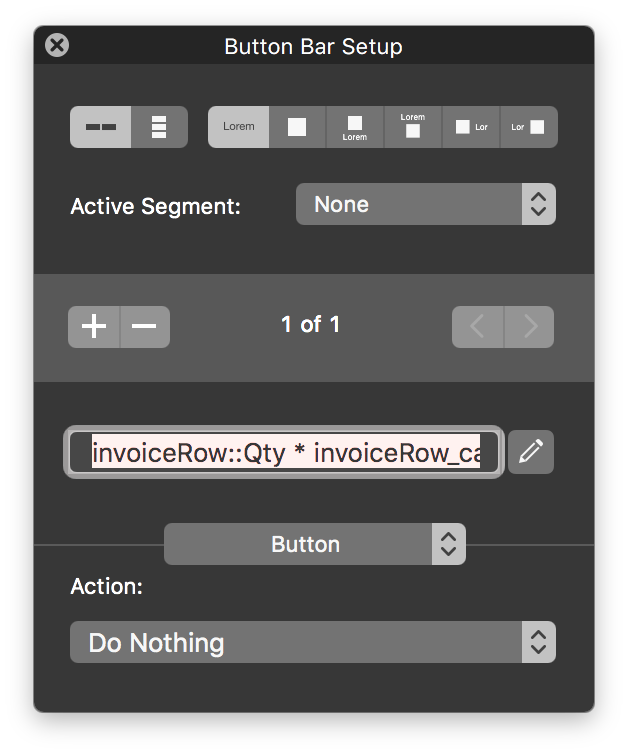
Since FM14 came out with the new button bars having the ability to calculate data on the fly on layouts for display purposes has been great - the fact that you can display data without a dedicated calculated field or extra relationships just to display a bit of information. So I am generating a document that prints a portal however the data is not connected to the portal in the traditional parent / child relationship - but rather it's showing related data for the given product kits. This invoice line item record is not "parent" to the portal of kit items. That presented a challenge - originally i had a convoluted way to generated this report using a virtual list but the it required a bit more effort to generate, so how to get totals to display properly in the portal row to multiply quantities - and to also show a total of items packed? One thought would be to put global fields in to the kits lookup table and then set them which would drive keys to the data tables via dedicated relatiohships just prior to generating the report, but that just felt awkward. Here is what I came up with. The row of 6 kits are what the customer ordered based on this there needs to be 108 pieces based on the piece count for each item in the kit multiplied by the quantity ordered. Example 6 x 12 = 72 as you can see by the first row in the portal. To get the value of the 72 I added a singe segment button bar to the portal and multiplied the 6 by the 12 pretty simple. This was all great but I also needed to get a total for the total items packed but that is based on yet another table not directly tied to the kit table. So by adding a second calculation button segment and this formulae I was able to get the necessary data. Hope you find this useful. Cheers.
 3 points
3 points -
I don't see anything "unusual" in this numbering scheme. This question comes up quite often: you have a parent-child relationship, and you want to number the children of each parent with its own series (prepending the other digits representing the parent ID and the year/month is trivial). Usually, the idea is to take the maximum existing value in the series (available either from the point-of-view of the parent, or through a self-join relationship of the child table based on matching parent ID), and add 1 to that. Which will work 99.9% of the time - until two users create records roughly at the same time and end up with duplicate numbers. So the first "challenge" is to prevent such situation - and it could be accomplished by (a) forcing the users to create new child records by script only, and (b) having the script lock the parent record first and, failing to do that, abort the task. However, the "challenge" doesn't end there: you must also consider what will happen if user decides that the parent selected initially is not the right one and needs to be changed to another. Instead of dealing with this, let me also point out that if any record is deleted, you will have a gap in the series anyway. So the real question I would ask here is this: is the goal worth the means required to achieve it?3 points
-
I would say that the idea is to append something to the values that do not end with the specified suffix. This is done in three steps: Protect the values that do end with the specified suffix from being modified in step 2 by substituting the suffix and the subsequent return with a reserved character (a); Substitute all remaining returns with a reserved character (b) and a return; this effectively appends (b) to all values that do not end with the specified suffix; Reverse step 1 . The result of this is indeed what you show in your post: [email protected] [email protected](b) [email protected] [email protected](b) [email protected] and when this is used to filter the original list, only the unmodified, wanted values remain. IIRC, I developed this idea out of something that Agnès Barouh did, I don't recall exactly what that was.3 points
-
Try it this way = Let ( [ suffix = "gmail.com" ; list = Substitute ( YourField; ", " ; ¶ ) ; a = Char (57344) ; b = Char (57345) & ¶ ] ; FilterValues ( list ; Substitute ( list & ¶ ; [ suffix & ¶ ; a ] ; [ ¶ ; b ] ; [ a ; suffix & ¶ ] ) ) ) The result will be a return-separated list of the matching addresses: [email protected] [email protected] [email protected]3 points
-
3 pointsI did a video with Richard Carlton http://filemakervideos.com/filemaker-14-svg-icon-helper-tool-filemaker-14-training/ about SVG files and created a small helper tool. In that video, I explain why I set the fill color to white, so that the icons appear nicely in the FM icon palette. You can see in the helper tool, how I did it and change to whatever you like, since it is completely free and unlocked.3 points
-
I do not see the need to 'down-rate' Rick for his question, liltbrockie. I have up-rated his post to offset it.3 points
-
One reason it's best to use records for things that are alike* is that records can easily be organized into sets (found or related) and these sets in turn are easy to sort and aggregate. Another point is that 5 is not a magic number. When you have 5 of something, you are likely to also have 3 or 4 and - eventually - 6 or 7. Now, records are very easy to add by the user, while adding fields requires the developer to change the schema. --- (*) Numbered fields are almost always an indication that you are dealing with several things that are alike.3 points




















This leaderboard is set to Los Angeles/GMT-07:00